Taskqueues are used to asynchronously run tasks (indistinctly called “jobs”). They are very useful to enqueue actions for later processing in order to preserve short response times. For example, during the signup you may want to send the confirmation mail asynchronously. Or you may have a slow task to generate an export file instead of doing it inline.
As a website grows, the need to use a taskqueue often arises. The general architecture usually looks like this:

Clock or a Scheduler)All the main web languages have several: Celery, RQ, MRQ (Python), Resque, Sidekiq (Ruby) …
The main qualities of a framework are:
Workers generally execute the same codebase as the app. This is the source of many problems, since the codebase is not optimized for this context. Workers aim at high throughput but Ruby and Python default implementations are single-threaded. Also, tasks often interact with unreliable third party services, so they have to be very resilient.
We use a taskqueue extensively at Drivy, so we have some tips to share!
Most importantly, tasks should aim at being re-entrant. This means that they can stop in the middle and be ran again in another process. This is important because jobs may raise exceptions in the middle and be retried at a later time. Workers may also crash and restart. This often means that your tasks should be stateless, and not expect the DB to be in a certain state at processing time. They should be responsible for checking the state before running their actions.
Tasks should try to be idempotent. This means that running them several times (consecutively or in parallel) should not change the final output. This is very convenient, so that you’re not too scared if a task gets enqueued or processed multiple times.
It is also a good practice that tasks require the least number of arguments possible. For instance, you can only send a model ID instead of sending the whole serialized object. This gives you better predictability and easier visibility.
Additionally, if you want workers to run in multiple threads, you should be careful to design thread-safe tasks. Specifically, you should pay attention to the libraries you use, they are often the culprits of unsafe calls.
Example of unsafe Ruby code:
class SomeTask < ResqueTask
def self.perform(value)
Util.some_opt = value
Util.do_something
end
endClasses are instanciated process-wise. So when you run multiple tasks in parralel, Util.some_opt will be the same process-wise. This can lead to many problems.

Here is the same code refactored not to use class level calls:
class SomeTask < ResqueTask
def self.perform(value)
util = Util.new(value)
util.do_something
end
endHere is another example of unsafe code in Python:
class SomeTask(MRQTask):
some_list = []
def run(self, params):
some_list.push(params["value"])When ran in parallel, some_list will be the same process-wise. A simple way to fix it is to instanciate missing params inside the task perform method:
class SomeTask(MRQTask):
def run(self, params):
some_list = []
some_list.push(params["value"])We often misunderstand the exact behaviour of our backend task storage systems. It is often a good idea to take the time to read the specs and the open issues of the system you use.
Each broker library has its own trade-offs in terms of delivery atomicity. Exactly-once is the guarantee that each message will only be delivered once.
Few systems can provide this, and some would say that it’s infeasible in a distributed environment.
Most systems provide at-least-once or at-most-once delivery guarantees. You therefore often have to handle redundant messages delivery.
Also, a broker should have a good resiliency to crashes. You don’t want to loose tasks on system crashes. If you use in-memory storage systems like Redis, you should backup regularly to the file system if you don’t want this to happen.
In some cases, tasks enqueuing calls may get entirely discarded: the webapp (or the CRON) tries to enqueue a task to the broker, but the call fails. This is obviously a very bad situation, as you’re going to have a very hard time trying to re-enqueue the lost tasks afterwards. If the volumes are high, or if the failures are silent, then this quickly turns into a catastrophic situation.
One situation where this can happen is when the broker exceeds its storage capacity. You should foresee this happening. A common issue causing this is to pollute your broker with metadata: very long arguments, results, logs, stacktraces …
Having network issues with the broker can also become a very painful point, especially since it’s often random. You should try and design your infrastructure to have as little latency as possible between the app and the broker.
A very good advice is thus to monitor your broker’s system in depth, looking at the different metrics and setting up alerts. You can also look for SaaS hosting for your brokers as they often provide out-of-the-box monitoring solutions.
Workers can have different configs depending on what type of tasks they perform. For instance:

You usually try and optimize your different workers and queues to be able to dequeue everything in time at the lowest cost possible.
Here is an example of a queuing strategy:

(the number on the arrows represent the queue priority for each worker)
There is no one-size-fits-all solution for optimizing this. You’ll have to iterate and find out what works best for your tasks with your specific workers. You’ll have to change it over time as you update tasks and their mean runtime evolves independently. Again, monitoring is absolutely necessary.
At Drivy we have decided not to name our queues after the bit of logic they handle. We don’t want to have a mail queue or a car_photos_checks queue. We think it’s more scalable to group tasks in queues depending on their properties: mean runtime, acceptable dequeuing delay. So we have queues like urgent_fast or average_slow.
Here is a common bad day scenario:
These sort of situations will necessarily happen. You should not try and avoid them altogether but at least be monitoring this, and be ready to take some actions.
Your monitoring system should be able to alert you when queues don’t respect their SLAs anymore. Being able to scale lots of worker quickly will help you. Try and know your limits in advance so you don’t overload a resource or consume all the network bandwidth. Auto-scaling is not easy to setup at all, don’t rely on it at the beginning.
Here is a common list of things that can go wrong:
You absolutely need to handle soft shutdowns: receive the signals, try and finish tasks in time, and requeue them otherwise. Your workers should also feature an auto-restart feature, so that the congestion doesn’t get out of hand to quickly.
Memory leaks may also happen. Depending on the volumes, this may grow quickly and workers may crash. (be aware that Heroku Errors like Memory Exceeded are not monitored by error trackers like new relic). Debugging memory leaks is very hard. It’s even harder in taskqueue systems, so try and find the right tools for your stack, and arm yourself with patience.
Syntax errors can go undetected: the CRON system is rarely ran in development and even less covered by tests.
You may also encounter runtime errors e.g.: argument computed on the fly fails. This can easily go undetected as we often run the clock as a background process of a proper worker.
To avoid this, you should try and keep the CRON as simple as possible: it should only enqueue tasks with hardcoded arguments. It should not fetch anything from external resources, like the DB.
Two good practices that can help:
Tasks will raise exceptions. You cannot and should not cover in advance all cases. User input, unexpected context, different environments are just a subset of the problems that you cannot forecast.
You should rather focus your efforts on tracking. Using a bug tracker service (Bugsnag, Sentry, ..) is a very good idea. You should have a middleware that logs all Exceptions to your bug tracker, and setup alerting from your bug tracker. You can then treat the bugs and create issues for each depending on their priority / urgency.
Here is how a bug tracker interface (Bugsnag) looks:
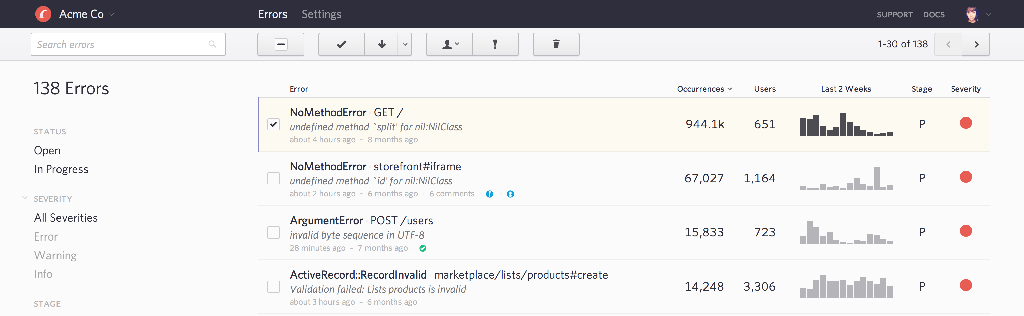
Most tasks should be retried several times before being considered as properly failed. If your tasks respect the contracts from Tip 1, it should not be a problem to retry tasks by default.
Different tasks may have different retry strategies. All I/O calls (especially HTTP) should be expected to fail as a regular behaviour. You can implement increasing retries delays to handle temporarily unavailable resources.
Depending on the tasks, workers may hit the DB way harder than a regular web process. Try and estimate how hard before scaling your workers. You may also hit connections limits quickly: namely your SaaS provider connection limit, or your system’s ulimit.
A good practice is to use connection pools in your workers, and to be a good citizen: release the unused ones, reconnect on deconnections … Dimension these pools according to your DB limits.
Another very alleviating solution is to use slave databases in your workers: a task may then never slow down your product. However, you have to be careful with the possible replication lags. It is sometimes necessary to kill workers while the slaves are catching up with their masters.
Workers are very cheap nowadays, so you should be better off investing time into monitoring than optimizing your tasks and queries.
This was initially given as a meetup talk, see the slides here: http://adipasquale.github.io/taskqueues-slides-2015.